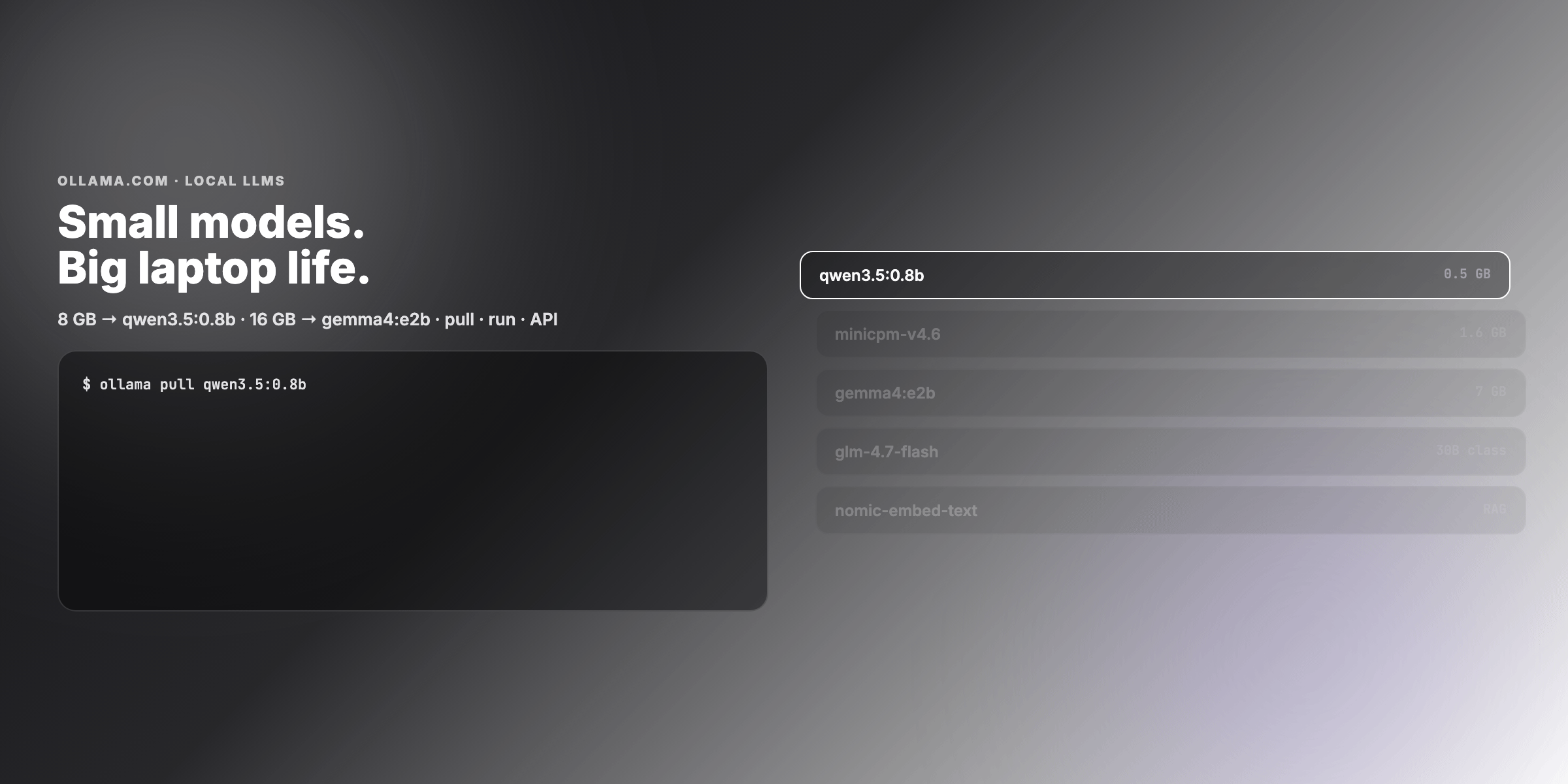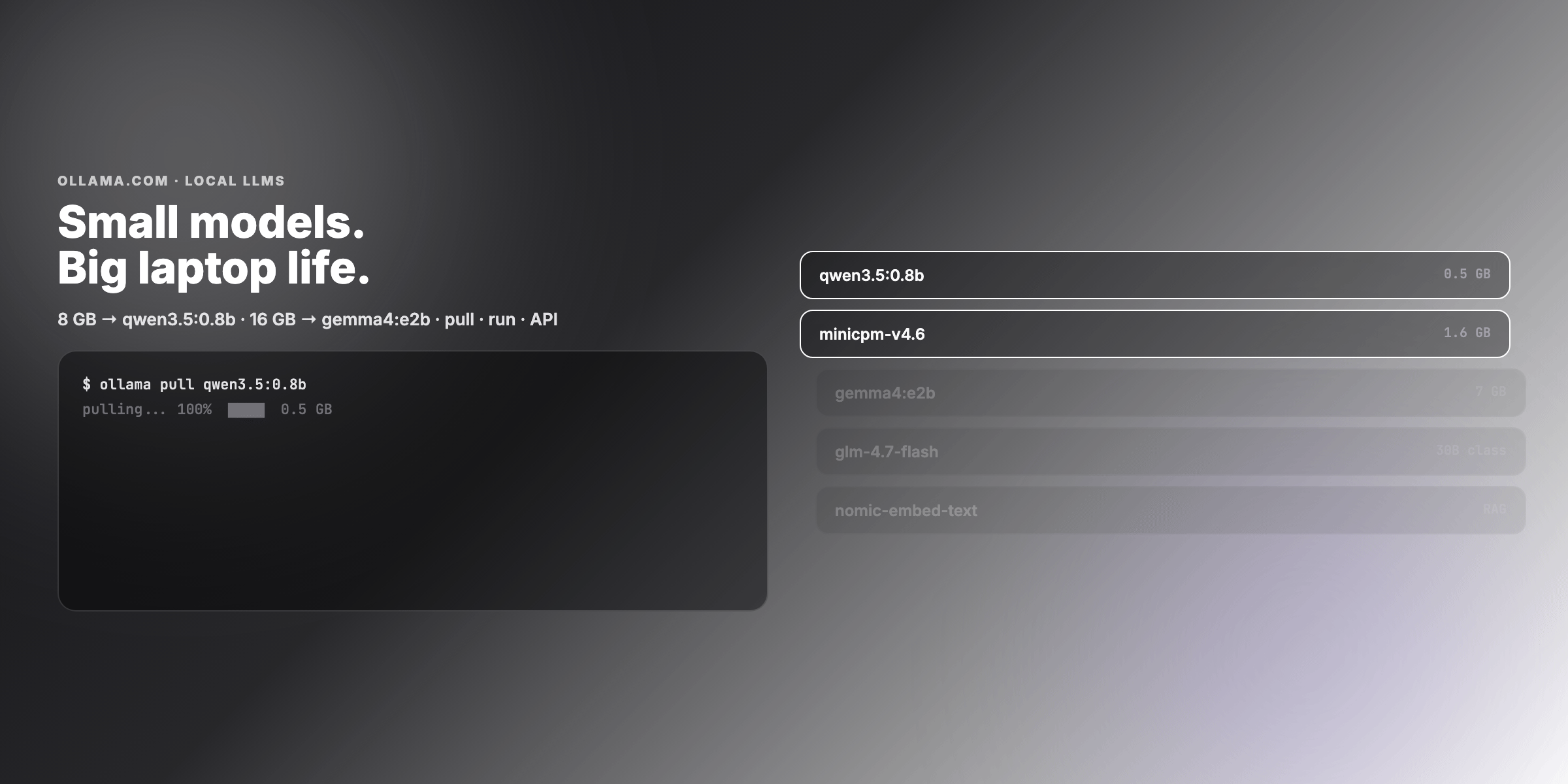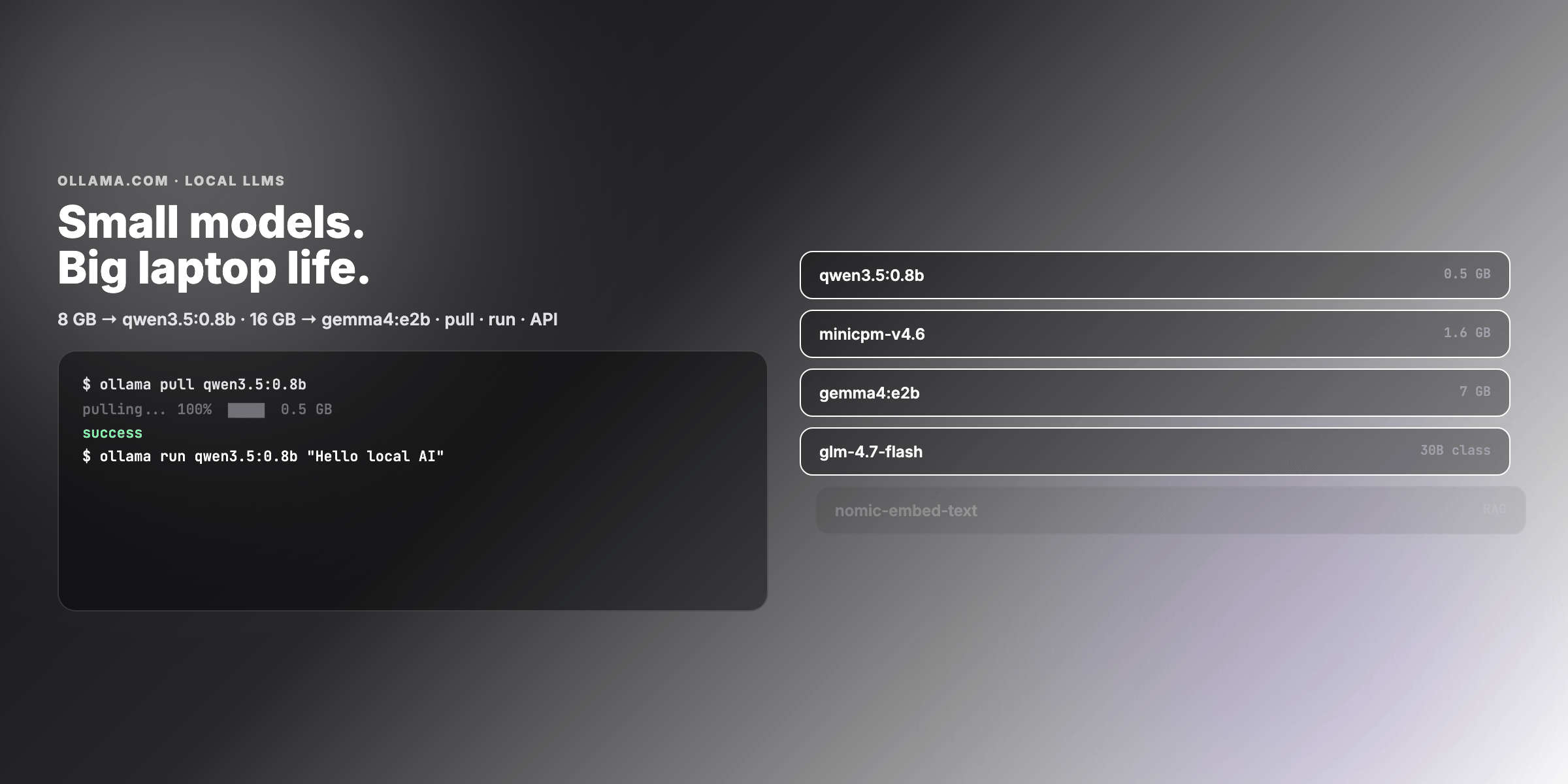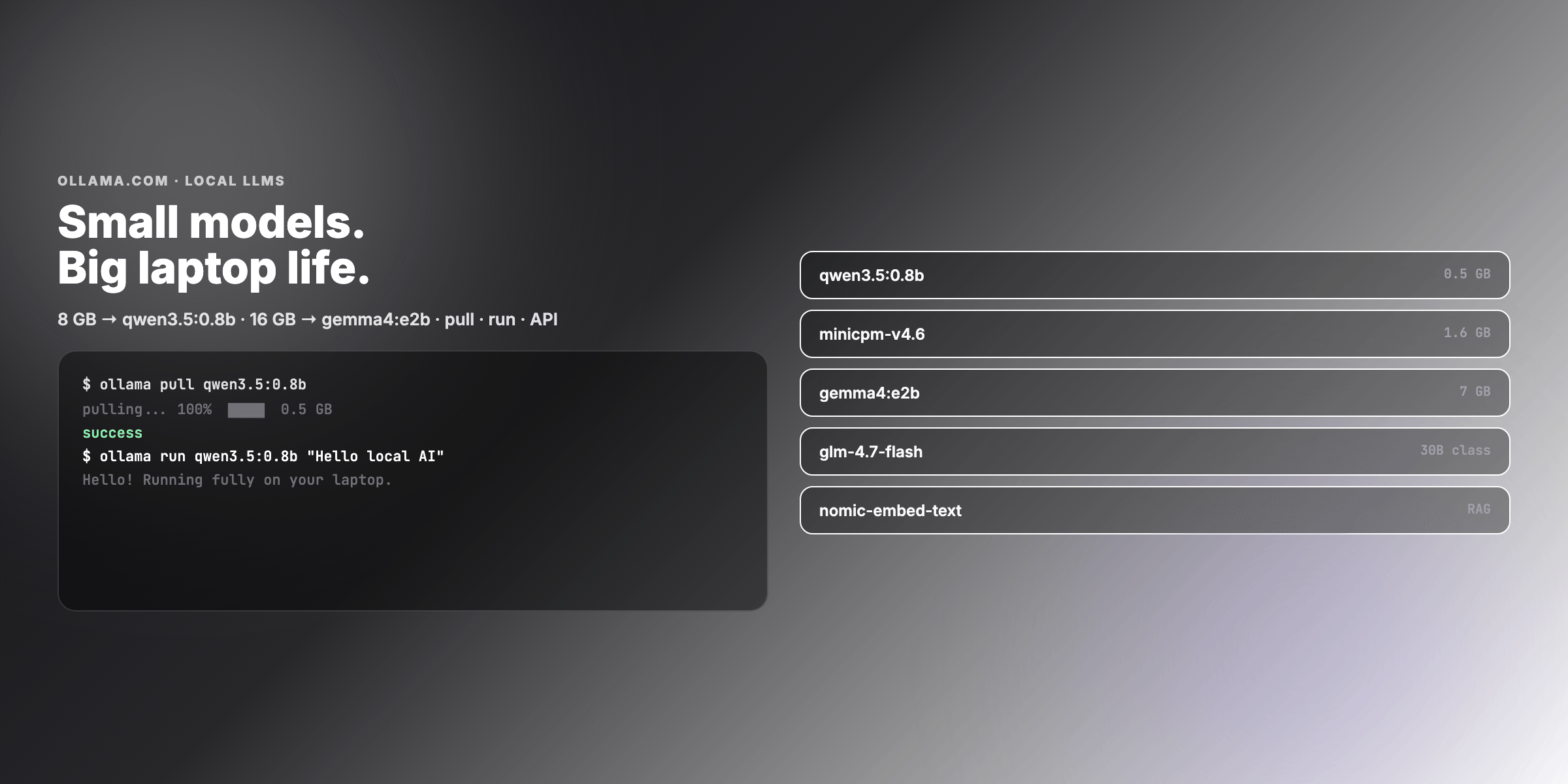
Overview
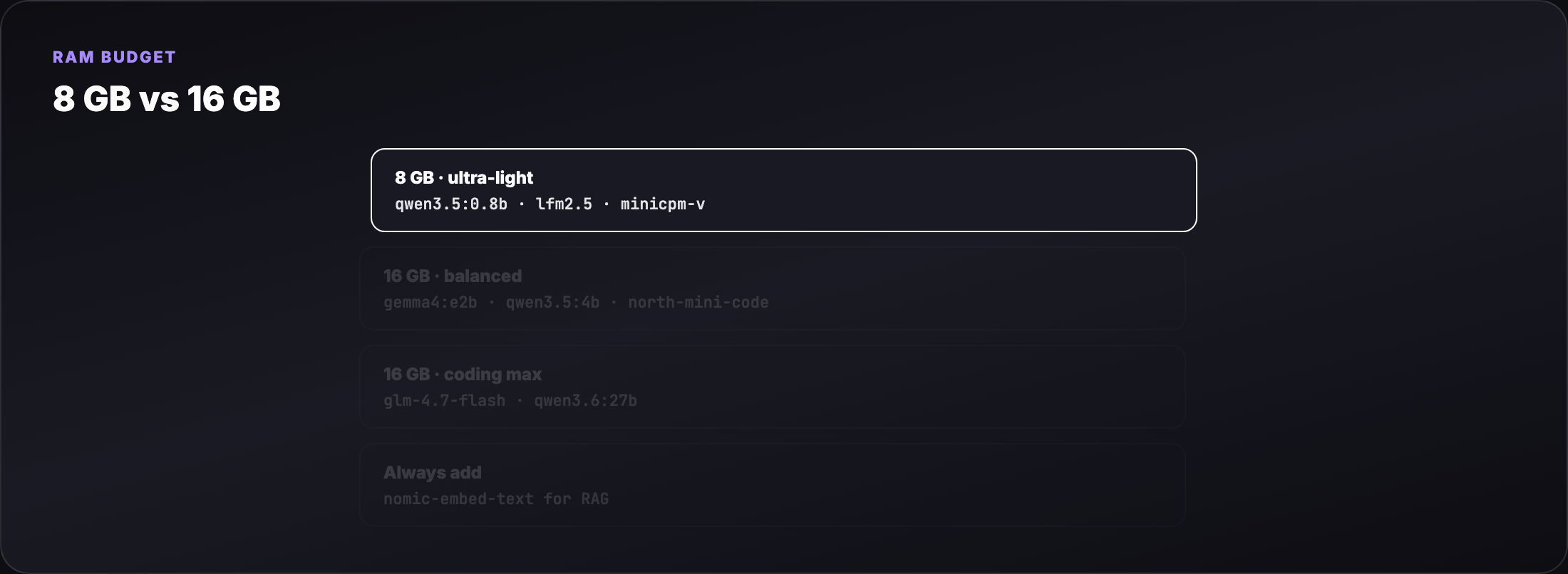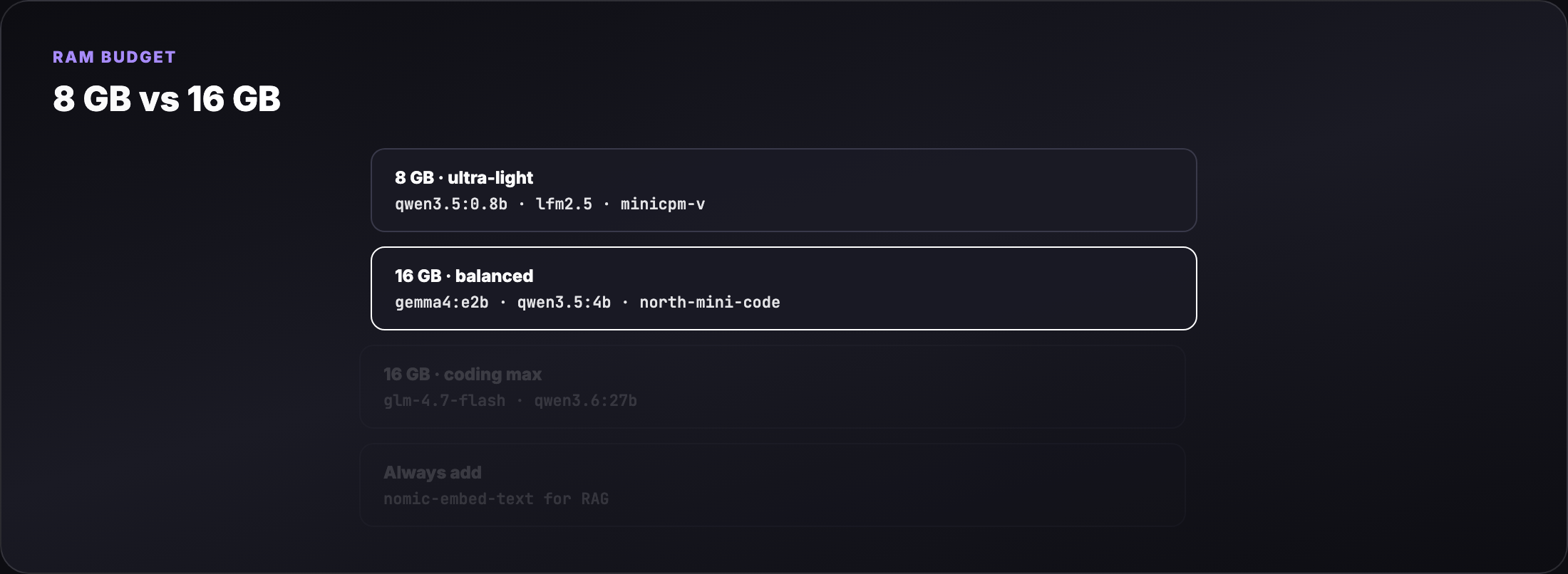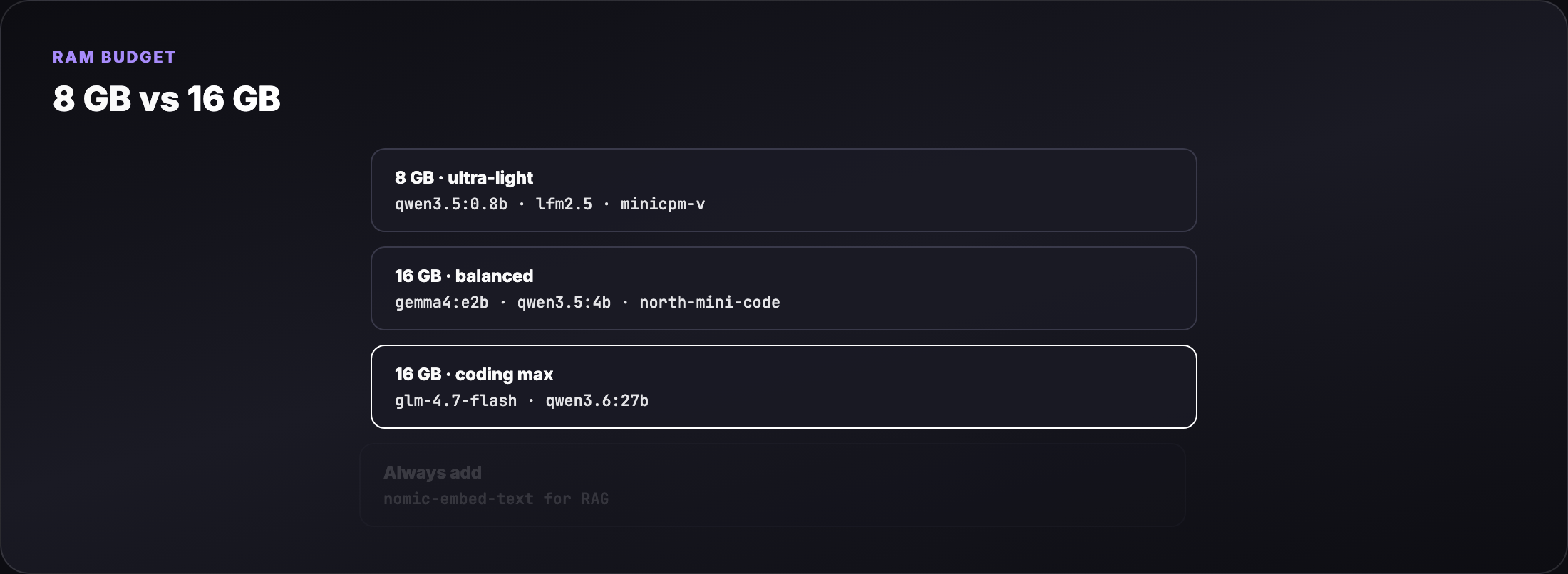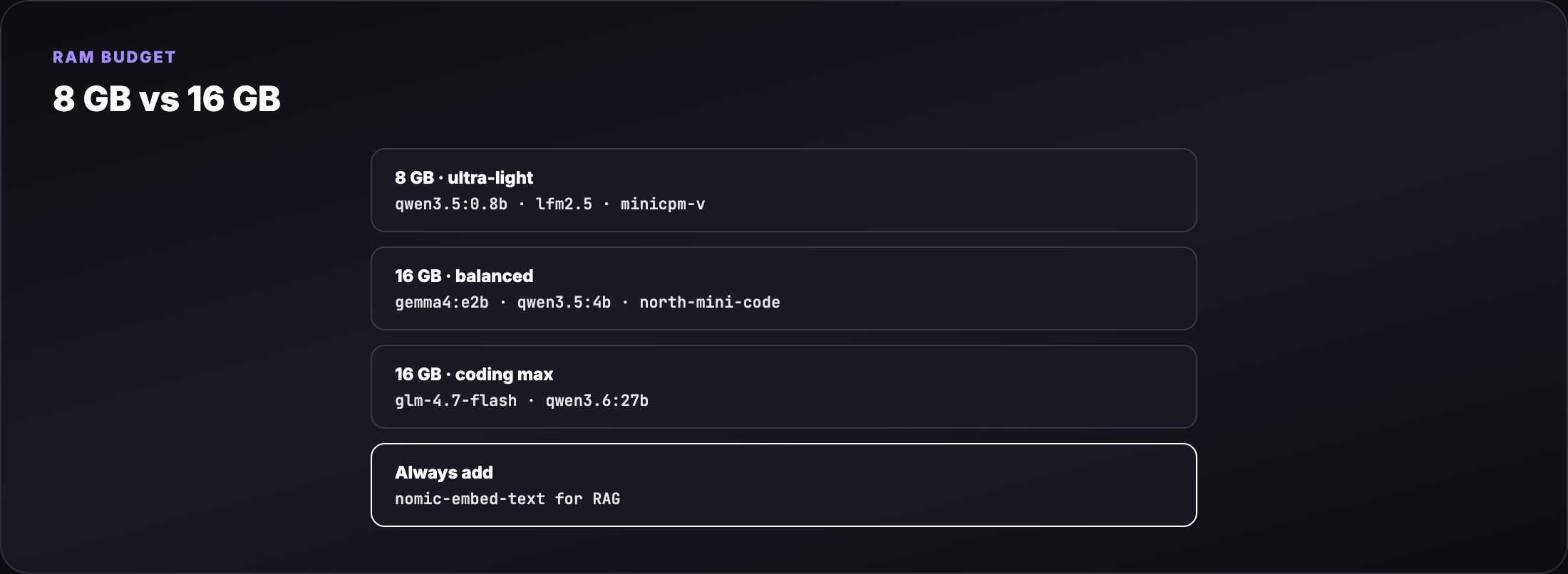
- Which Ollama tags fit 8 GB vs 16 GB laptops (disk size ≠ RAM at inference)
- New 2026 models: Gemma 4, Qwen 3.5/3.6, GLM-4.7-Flash, LFM2.5, MiniCPM-V, North Mini Code
- Terminal workflow:
ollama pull→ollama run→ streaming response → REST API - Task-specific picks: chat, coding, vision, embeddings, tool/agent loops
- Wiring models into OpenClaw, PicoClaw, and MCP stacks
One-GIF overview (blog hero): mega-ollama-small-models.gif
{kind=link}
- Full tutorial — Parts 1–16 (RAM math → model catalog → agents)
- Examples — pull scripts for 8 GB / 16 GB, OpenClaw snippet, Modelfile
- Assets — diagram + terminal GIFs (pull, run, response), blog poster